
Denoising Autoencoder for Bioacoustic Applications
This work was part of a final project for Harvard’s graduate class CS281: “Advanced Machine Learning”, fall semester of 2019, done together with Petur Bryde, Tyler Piazza, and Serges Saidi. This description summarizes the components I was responsible for.
In this project, we aim to contribute to efforts for environmental monitoring through deployment of acoustic sensors by drawing on work from deep-learning-based audio and image enhancement to isolate birdsong from background noise. Bioacoustic monitoring systems have become increasingly common in recent decades, as they could greatly save time and resources over manual population surveys. Yet they do introduce a new technological challenge: how can birdsong be identified and classified within many hours worth of audio recordings? This is an active area of research (see [Stowell et al, 2016] [Priyadarshani et al, 2018] for reviews) and has been the subject of several public data challenges [Stowell et al, 2018] [BirdCLEF]. One of the biggest barriers to successful classification systems is the presence of highly time-variant and region-dependent background noise. We are interested in whether it is possible to reduce noise levels with the use of a convolutional denoising autoencoder (CDAE).
First, we construct a dataset on which to train our system. A major difficulty of implementing acoustic foreground-background segmentation on natural data is that the ground-truth will generally not be available. In particular, for our application, we do not expect it to be possible to collect recordings of birds in the wild without simultaneously capturing the surrounding soundscape. On the other hand, given a foreground and background, it is very easy to construct the overall mixed signal. Therefore, by collecting separate recordings representing candidate background noise and candidate birdsong, we can artifically construct viable mixed recordings.
For the foreground components, we collected tracks from the Berlin Natural History Museum online database. While this resource only provides around six-and-a-half thousand recordings – which is small in comparison to Xeno-Canto, which contains hundreds of thousands – the audio is consistently high-quality, with low background noise content, which is very important for our application. The recordings cover 273 species, and are usually between 0 and 2 seconds in length. For the background audio, we utilized recordings from the BirdVox detection challenge dataset. The challenge contained twenty thousand 10-second recordings collected around Ithaca, NY, by researchers from the Cornell Lab of Ornithology, and were labeled by whether the tracks contained birdsong. We filtered and collected all tracks without birdsong to form “background” audio. To compose a mixed track, we first took a distinct 1-second window of the background track and normalized it to a unit maximum amplitude. Then, we randomly sampled two birdsong files, normalized, and added them within randomly sampled locations in the background track (resulting in a signal-to-noise ratio of 0.5).
Generally, studies of audio convert the acoustic time series into a two-dimensional time-frequency representation – a spectrogram – which provides a more informative view of the properties of sound. For all of the datasets used, we constructed spectrograms using a sliding Short-Term Fourier Transform (STFT) with a Hanning window. While it would be interesting to reconstruct the processed audio time series based on our model output, we did not do so in our work.
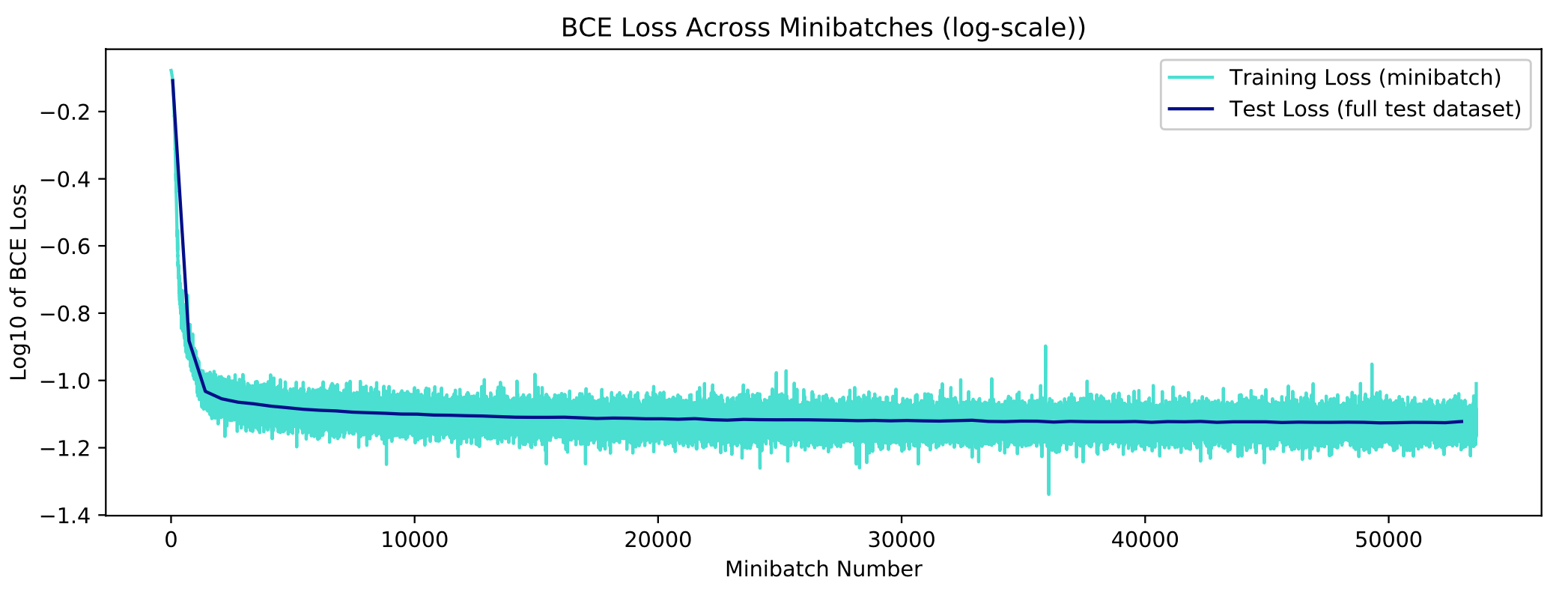
We then implemented a convolutional denoising autoencoder (CDAE), such that spectrograms containing both background and foreground signals would make up the input to the network, and would be trained against the clean birdsong foreground. The encoder and decoder both contained one hidden layer layer, and all layers were joined with ReLu operations and 2x2 pooling layers. The number of channels per inner layer was varied to compare performance. We used an 80-20 training-testing split across the datasets. The spectrograms, initially of size 100x426, were rescaled to a size of 24x100 to reduce the dimensionality of the network. Additionally, they were normalized to a maximum amplitude of 1 for compatibility with binary cross-entropy (BCE) loss, a common loss function for image denoising. All models were run on a Tesla K80 GPU through Google Colaboratory. Parameters were chosen by manual tuning.
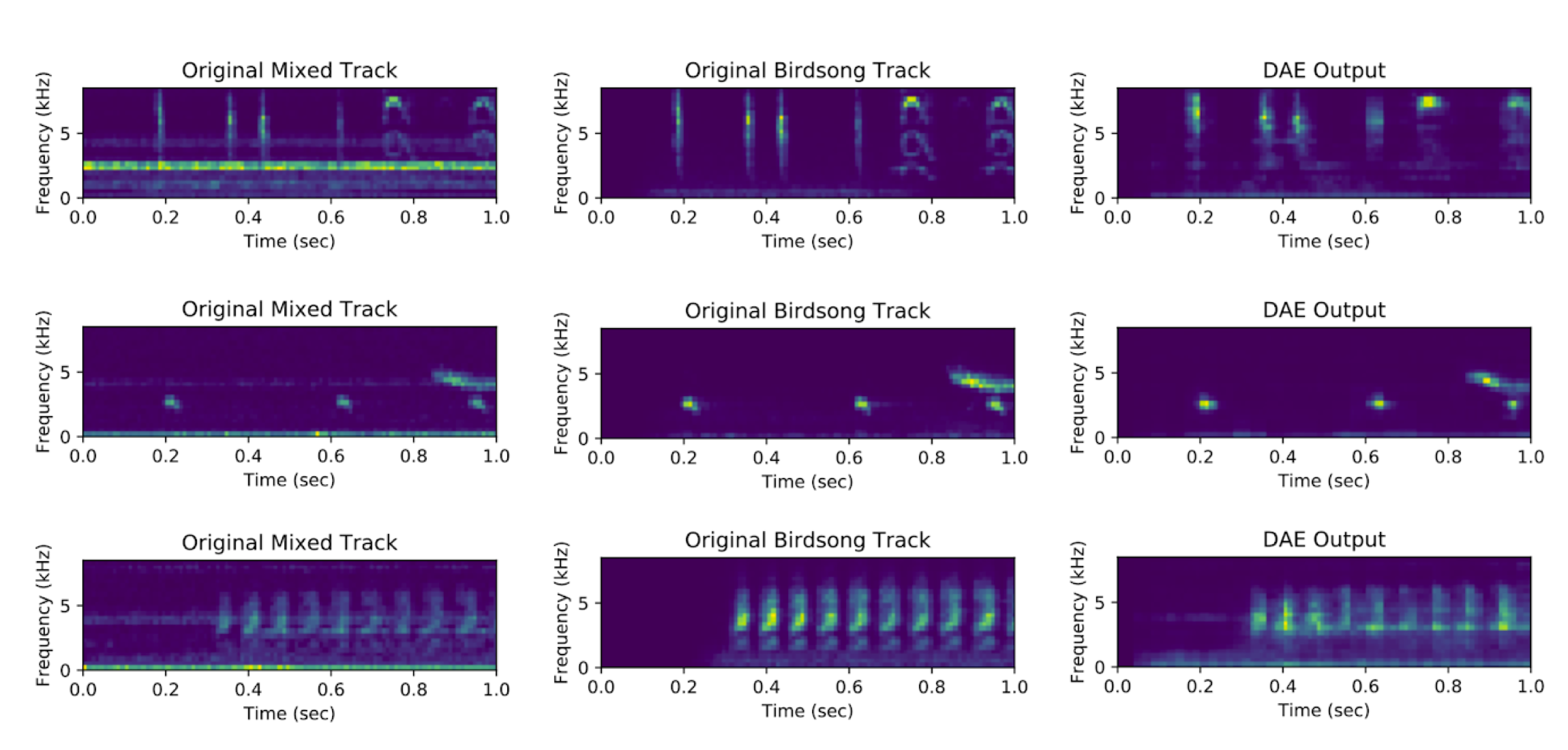
The top figure shows the BCE loss of the network across minibatches. The bottom figure shows several examples of the input (noisy) spectrograms, the ground-truth birdsong spectrograms, and the autoencoder output for the synthetic and realistic datasets (respectively), on instances from the test dataset.
All in all, we have successfully implemented, evaluated, and analyzed an approaches for isolating birdsong in acoustic recordings. For future work, it would be interesting to evaluate the quality of the audio reconstructed from processed spectrograms. Additionally, while we were limited by time and memory constraints, future studies could construct larger datasets to train more complex networks with higher representational ability. We hope that this work will contribute to the development of acoustic monitoring technologies and further avian conservation efforts.